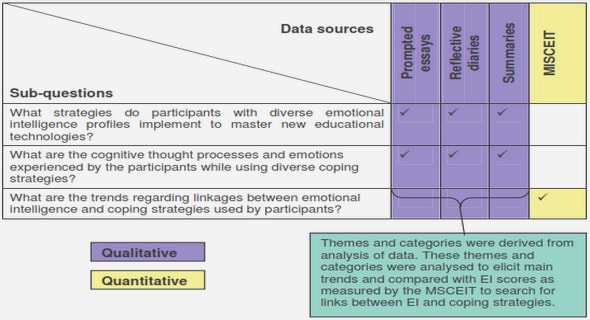
Get Complete Project Material File(s) Now! »
Data and Framework
Sample and remarks
The chosen sample was 98 of 98 Danish municipalities in mainland Denmark. The reason Danish municipalities was chosen is due to the large availability of accurate public statistical data and as a member of a Nordic country could be interesting to compare to previous studies on the Nordic region. In 2007, Denmark went through political reforms regarding municipalities which decreased the number of municipalities from 270 to the current 98. More than 98 percent of the Danish population is considered, with the missing two percent containing data from the Faroe Island, Greenland, Ertholomene as this data was omitted from the Danish municipality data records. Due to this the earliest reliable and accurate municipality data starts from 2007. That being said, the chosen years for the study was 2008-2016, making a nine-year period. The rest of the data set comes out to be strongly balanced (no data is missing throughout all time period) for the 98 municipalities over the nine-year span 2008-2016.
The spatial unit of municipality was chosen among other spatial units such as regions or labour markets. Labour markets can be argued to be a much more comprehensive study of the working population of an area as opposed to municipalities. A person who lives in a certain municipality could be working and earning their income in a different municipality and would therefore not be concerned whether income growth is increasing/decreasing in the municipality where they live; rather the municipality they work in. A good example would be Rooth and Stenberg (2012), who, used Statistic Sweden’s data of Swedish labour markets, who reduced 290 Swedish municipalities into 72 labour markets. The advantage of using labour markets is that each allocated region is similar in terms of demographic functions, public transfer systems, educational systems, labour market institutions and access to health care, while municipalities are more divided and allocated for administrative purposes rather than economic (Rooth and Stenberg, 2012). This being said, the reason labour markets have not been choose as the spatial unit for this report is due to the laborious method in which they divided the municipalities into regions. Rooth and Stenberg used commuting patterns of workers to determine their labour markets; such data was not available for Denmark. It is also unclear how Rooth and Stenberg went about dividing the labour markets after the commuting patterns data was obtained. Secondly, in Sweden there exist 298 municipalities which vary from a population of 2,400 in Bjurholm to 900,000 in Stockholm, with more than 100 of these municipalities are under 20,000 in population. Whereas in Denmark, the number of municipalities in much more condensed into 98, where only seven of the municipalities have under 20,000 inhabitants. In this case, although the municipalities are administratively divided it gives a more comprehensive economic layout than what it initially seems.
Variables
All data retrieved from Danish statistics bureau: StatBank Denmark
The log of annual income per municipality, log( ), was chosen for this paper since the purpose to see how inequality and which factors of inequality could potentially affect economic growth. The average income growth rate of a municipality is a good indicator to show economic wellbeing of said municipality. The income that was taken was the pre-tax income for the working population aged 14+ in Denmark.
Figure 3 demonstrates that there exists a positive correlation between average income growth and Gini coefficient for the Danish municipalities between 2008-2016. Most municipalities group around the 1.56 percent income growth rate, and a Gini coefficient of 25.7. One of the major outliers in this figure is the municipality of Gentofte, who in 2015 reported an income growth of 15.33 percent and a Gini coefficient of 43.97. Gentofte is again an outlier posting a – 5.23 percent decrease in 2016 and Gini coefficient of 47.77. The last outlier is the municipality of Hørsholm who reported a -8.10 percent decrease in income in 2008 with a Gini coefficient of 37.51, but picked up two years later with 15 percent increase in income in 2010. Similar figures showing positive relationships between the 90/80 income ratio and the 50/10 income ratio versus annual income growth can be found in the appendix under Figure 7 and Figure 8.
For measure of inequality, the Gini coefficient Gini, which is a measure of statistical dispersion made to measure the income distribution on a national or regional scale, is used. The Gini coefficient lies on a scale between 0 and 1, where 0 signifies perfect equality while 1 signifies perfect inequality although for the purpose of this paper StatBank Denmark has multipled the coefficient by 100, leading to 0 signifying perfect equality while 100 signifies perfect inequality. Furthermore, as has been done in Rooth and Stenberg (2008) and Cialani (2014) the income share ratios of the 50th and 10th income deciles help us see the effect of income inequality at the lower end of the income distribution. Similarly, the 90th and 80th income ratio will be used to see how income inequality effects those at the top end of the income distribution.
Earlier studies on similar fields suggest that local policy making has an effect on growth rate of average income (Gleaser et al., 1995; Helms, 1995; Aronsson et al., 2001). The effects of local spending are encapsulated with the variables of Exedu, Exchild, Exeld, and Tax. The variables Exedu, Exchild, and Exeld, to a certain extent, cover local public expenditure of overall Danish national policy in terms of local municipality spending. The variable Tax is given by the municipality income tax rate. Helms (1985) finds that taxes have a negative effect on the income growth rate on 48 of 50 states in the USA. William Gale (2014) also did a study on the impact of income taxes on economic growth in the USA and like Helms, found that taxes have either negative or negligible effect on economic growth.
Public expenditure is controlled for with the variables of ExEdu, the amount of public expenditure spent per pupil, ExEld, the amount of public expenditure spent per elderly, and ExChild, the amount of public expenditure spent per child; all done per municipality. Aronsson et al. (2001) found that public expenditure per capita does not have a significant impact on income growth on a county level, as did Barro (1991) on a national level.
Human capital in the form of education would also be expected to increase the average income of an area. The variables which control these parameters are EduYears, the share of population with at least a bachelor’s degree. Papers by Jamison et al. (2007) and Krueger and Lindahl (2000) both corroborate that more years in higher education positives correlates to higher levels of income growth.
The variables of Dens and Age65 are used, in line with papers such as Nahum (2005) and Cialani (2014), in order to control for the degree of urbanization and the age structure of the population in the municipalities.
Descriptive statistics
Table 2 provides descriptive statistics of all the dependent and independent variables. Table 2.1 is a condensed version of Table 2 showing more vital descriptive statistics. As can be seen from the table the mean value of the Gini coefficient across all municipalities from the 2008-2016 is 25.70. The values across municipalities and over time, range from 20.40 to 47.77. The Gini coefficient of 47.77 belongs to Denmark’s wealthiest municipality Gentofte in the year 2016. Gentofte throughout the years of 2008-2016 consistently reported the highest Gini coefficient out of all other municipalities, while also reported the highest average income for the years of 2008-2016 implying a correlation between the two. To compare extremes, the lowest Gini coefficient of 20.40 belongs to the municipality of Egedal. Egedal was consistently near the bottom reported Gini coefficient throughout 2008-2016, and was placed into the top 15 average highest incomes for the years 2008-2016. This shows a contrasting relationship with that of Gentofte since Egedal’s Gini coefficient is less than 27 than that of Gentofte’s despite that both of them rank in the top 15 municipalities with highest income in Denmark. The lowest earning municipality was Langeland which was on average the bottom earning Danish municipality across 2008-2016. Langeland also placed consistently near the bottom of the Gini coefficient distribution with all their Gini coefficients landing in the bottom 100 out of all 882 observations of all Gini coefficients. A reason for this could be that Langeland is an isolated small island, and so is not connected to the large main islands of Denmark.
There also exists seems to exist a relationship between geographic location and income as can be seen in Table 3 (appendix). Thirteen of the top fifteen highest earning municipalities are all located in the Danish Capital Region, while the Southern Danish region holds three of the five lowest earning municipalities in Denmark. It is also worth noting that the municipalities with the top ten highest Gini coefficients are all located in the Danish Capital Region, indicating a geographical bias when it comes to income equality.
Turning to the other indicators of income inequality in Table 2.1 we can see that for the top income ratios, that of 90/80, the mean is 1.53 with a max value of 3.04 and a min value of 1.29. Following the trend of Gini coefficient and average income, the highest 90/80 ratio belongs to the municipality of Gentofte, which was also the highest earning municipality throughout the study. The lowest 90/80 ratio of 1.29 belongs to the municipality of Tårnby. Briefly looking at the bottom inequality ratio of 50/10, it shows the mean to be around 2.78, with a max of 62.97 and a min of -140. The reason for a negative number is because the StatBank Denmark recorded some of the bottom decile incomes as negative. Ignoring these anomalous negative numbers, we see the highest bottom inequality ratio of 62.97 belongs to the municipality of Hjørring, while the minimum lower income ratio of 1.91 belongs to Læsø, which ranks at 3rd lowest average income earner throughout the years of 2008-2016.
Looking at tax rates, we see that the mean tax rate is 25.21 percent throughout the years of 2008-2016. The range of tax rates is from 22.50 to 27.80, with the lowest belonging to Rudersdal for the years 2014, 2015 and 2016, which is also one of the highest earning municipalities throughout the studies. The highest tax rate of 27.80 belongs to Langeland, the lowest earning municipality throughout the years 2008-2016.
For the share of the population with at least a bachelor’s degree, the mean share of the population was 14 percent, with a minimum percent of 7.82 percent and the highest share of 35 percent. The lowest share belongs to Lolland in 2008, a sparsely populated island in Denmark’s southern region who rank among the bottom of the income distribution. The highest of 35 percent Frederiksberg in 2016, a municipality located in the heart of Copenhagen with a high density of educational institutions.
Methodology
Econometric Model
For this paper panel data analysis was the chosen method asses the data. Panel data allows for the use of cross-sectional and time-series dimensions, meaning that data can provide information across individuals and over time.
The regression equation, with Gini coefficient as the measure of income inequality is Equation 1: Regression Model Using Gini as Show of Inequality
( , ) = + 1 , + 2 , + 3 , + 4 ℎ , + 5 , + 6 , + 7 65 , + 8 , + ,
In this study Gini coefficient, as well as top and bottom inequality ratios, those of 90/80 and 50/10, be used as indicators of income inequality, as was done in Nahum (2005) and Cialani (2013). As these variables are measures of income inequality, they are set to be switched with the Gini coefficient as shown in Equation 2 and Equation 3.
Equation 2: Regression Model Using TopIncome as Show of Inequality
( , ) = + 1 , + 2 + 3 , + 4 ℎ , + 5 , + 6 , + 7 65 , + 8 , + ,
Equation 3: Regression Model Using BotIncome as Show of Inequality
( , ) = + 1 , + 2 + 3 , + 4 ℎ , + 5 , + 6 , + 7 65 , + 8 , + ,
A final model that will be used will incorporate both TopIncome and BotIncome to see how income affects simultaneously at the top and bottom end of the income distribution.
Equation 4: Regression Model Using BotIncome and TopIncome as Show of Inequality
( , ) = + 1 , + 1 , + 2 + 3 ,
+ 4 ℎ , + 5 , + 6 , + 7 65 ,
+ 8 , + ,
The dependent variable of (annual income DKK) will be logged in order to more easily interpret its coefficient when the panel regressions are run. As the all the independent variables are not transformed, the relationship between the dependent and independent is logarithmic-linear. This allows for the dependent variable to be interpreted as a percent increase (or decrease) rather than units of Danish Kronor. Therefore, the interpretation of the coefficients of my four models would be
%∆ = 100 ∗ ( − 1) or %∆ = 100 ∗ ∗ ∆ for simplicity.
Endogeneity Issue
The effects of income inequality on income growth could raise problems of endogeneity. Endogeneity is an issue where an explanatory variable could be correlated with the error term. Potential endogeneity issues arise from the inequality indicators; the estimated effect of income inequality on income growth could be biased via correlation between the income inequality indicators and the error term. If independent variables are endogenous and correlated with the error term, then it is possible that our OLS (ordinary least squares)/ FE (fixed effects) results could are biased and inconsistent.
There are multiple ways in dealing with endogeneity such as 2/3 SLS (step least square) regressions or System-GMM. This being said, no procedures to rectify the issue of endogeneity in my sample; simply stating that such bias could be present in my results, although not likely.
Tests for Model
Firstly, as this will be a panel data model due to having both cross-sectional and time-series components, the next question that arises is to which type of panel data model best fits the econometric analysis. When dealing with panel data multiple analysis models exist for regression analysis; the two most prominent being fixed effects models and random effects model. Several tests will be performed on previously stated models to see which is optimal for this study.
The Hausman test is a statistical hypothesis test, which tests to see if there exists a correlation between the errors and regressors in the model. Thus, the two hypotheses are:
0:
1:
Running the hausman test on Stata using Equation 1, leads us to the result shown in Figure 4 (appendix); using = 0.01 we can reject the null hypothesis at the 1% significance level and conclude that the fixed effects model is suitable for this data since < 0.01.
The fixed effects model is an econometric model which allows for the control of omitted variables/ unobserved heterogeneity that could otherwise influence results. Dummy variables for space and time (Danish municipalities and years in my case) are fixed to deal with omitted variable bias that could occur in standard regressions. The left over ‘within’ variations could help identify casual relationships.
Next, multicollinearity was tested for in the model. A correlation table, Table 4 (appendix), was made to see if any of the explanatory variables related to one another. As can be seen, since no variable exceeds the value of ±0.8 (excluding constant term) we can conclude there is no multicollinearity in Equation 1.
A further test for multicollinearity was done in the form of VIF (Variance Inflation Factor). As can be seen from Table 5 (appendix), none of the variables exceed VIF of ten, therefore we can conclude again that no multicollinearity is present.
To test for autocorrelation a Wooldridge test was used. The two hypotheses for this test are:
0:
1:
As seen in Figure 5 (appendix), using = 0.01 we can reject the null hypothesis at the 1% significance level and conclude that autocorrelation is present in this model since < 0.01.
To test for heteroscedasticity a Breusch-Pagan test was used. The two hypotheses for this test are:
0:
1:
As seen in Figure 6 (appendix), using = 0.01 we can reject the null hypothesis at the 1% significance level and conclude that heteroscedasticity is present in this model since < 0.01.
Since heteroscedasticity and autocorrelation were both detected in the model for Equation2 1, an appropriate solution to counteract these deficiencies is using robust estimators. Luckily, there exists a function on Stata that can automatically run robust fixed effects regression.
Contents
I. Introduction
II. Previous Studies
A. Kuznets’s curve and Gini in Denmark
B. Income Inequality Insignificant or Hindrance to Growth
C. Income Inequality Insignificant or Benefit to Growth
D. Similar Regional Studies
III. Data and Framework
A. Sample and remarks
B. Variables
C. Descriptive statistics
IV. Methodology
A. Econometric Model
B. Endogeneity Issue
C. Tests for Model
V. Conclusions
A. Empirical Findings
B. Limitations and Possibilities for Further Research
VI. References
GET THE COMPLETE PROJECT