Get Complete Project Material File(s) Now! »
Fixed-Budget Analysis
In this section, we compare the algorithms developed in this work with the classic RLS heuristic (which was the essentially best previous unary unbiased algorithm for Om) in the fixed-budget perspective, that is, we compare the expected fitnesses obtained after a fixed budget B of iterations. This performance measure was introduced by Jansen and Zarges [JZ14] to reflect the fact that the most common use of search heuristics is not to compute an optimal solution, but only a solution of reasonable quality. We note that the time to reach a particular solution quality, called TA,f (a) in [Doe+13a] where this notion was first explicitly defined, would be an alternative way to phrase such results. We do not regard this performance measure here, but we would expect that, in a similar vein in as the following analysis, also in this measure our algorithm is superior to RLS by a (small) constant percentage. Our main result in this section is that our drift maximizer with a fixed budget compute solutions having a roughly 13% smaller fitness distance to the optimum. This result contrasts the lower-order advantage in terms of the expected runtime, i.e., the average time needed to find an optimal solution.
Self-adjusting Mutation Rate
While it is clear that choosing the best mutation strength for each fitness level can improve the performance, it is not so clear how to find a good mutation strength function efficiently. To overcome this difficulty, we propose to choose the mutation strength in each iteration based on the experience in the optimization process so far. We enforce gaining a certain experience by designating each iteration with probability
as learning iteration. In a learning iteration, we flip a random number of bits (chosen uniformly at random from a domain [1..rmax]) and store (in an efficient manner) the progress made in these iterations. In all regular iterations, we use the experience made in these learning iterations to determine the most promising mutation strength and create the offspring with this mutation strength.
More precisely, let us denote by xt the search point after the t-th iteration, that is, after the mutation and selection step of iteration t. Denote by x0 the random initial search point. If t is a learning iteration, denote by rt the random mutation strength r used in this iteration. Otherwise set rt = 0.
Mathematical Runtime Analysis on OneMax
In this section, we analyze via mathematical means how self-adjusting algorithm optimizes the OneMax function. This is an asymptotic analysis in terms of the problem size n. We refer to the previous well-established runtime analysis literature for more details on the motivations of mathematical runtime analysis and on the meaning of asymptotic results.
Putting Everything Together
We can now put everything together to prove our main result. Proof. Starting with arbitrary initialization, Theorem 5.9 along with a Markov bound yield that with probability W(1) after t = O(n/ log ) iterations a search point is reached such that kt 2n/ and rt < 0.6(ln ). Assuming this to happen, the assumptions of Theorem 5.16 are satisfied. Hence, after another O((n log n)/) iterations the optimum is found with probability at least 1/2. Altogether, with probability W(1) the optimum is found from an arbitrary initial OneMax-value and rate within T = O(n/ log + (n log n)/) iterations. The claimed expected time now follows by a standard restart argument, more precisely by observing that after expected O(1) repetitions of a phase of length T the optimum is found.
Table of contents :
Résumé
Abstract
1 Introduction
1.1 Bit-counting Problems
1.2 Summary of Contributions
1.3 Related Work
2 Preliminaries
2.1 Black-box Complexity
2.2 Evolutionary Algorithms
2.3 Randomized Local Search
2.4 Drift Theorems
2.5 Chernoff Bounds
2.6 Occupation Probabilities
2.7 Useful Equations and Inequalities
3 Precise Unary Unbiased Black-box Complexity
3.1 Problem Setting and Useful Tools
3.2 Maximizing Drift is Near-Optimal
3.3 Fitness-Dependent Mutation Strength
3.4 Runtime Analysis for the Approximate Drift-Maximizer ˜A
3.5 Fixed-Budget Analysis
3.6 Self-adjusting Mutation Rate
3.7 Mathematical Runtime Analysis on OneMax
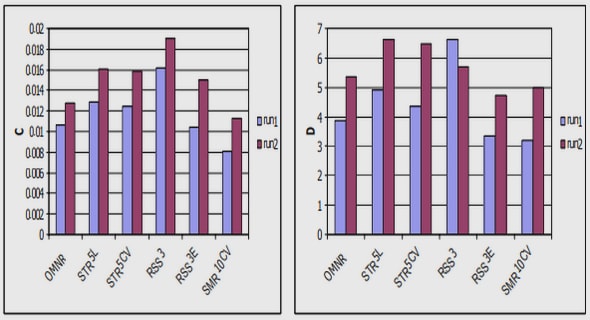
3.8 Experimental Results
4 Self-adjusting (1+) EA 63
4.1 Algorithm
4.2 Proof Overview
4.3 The Far Region
4.4 The Middle Region
4.5 The Near Region
4.6 Putting Everything Together
4.7 Experimental Results
5 Self-adapting (1,) EA
5.1 Algorithm
5.2 The Far Region
5.3 The Near Region
5.4 Putting Everything Together
5.5 Experimental Results
6 Conclusions
Bibliography