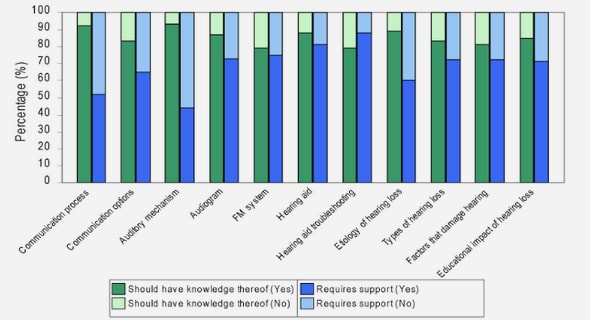
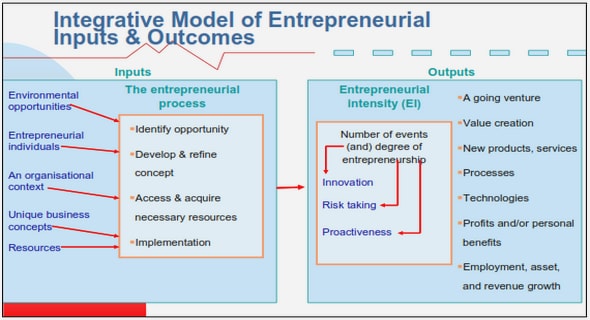
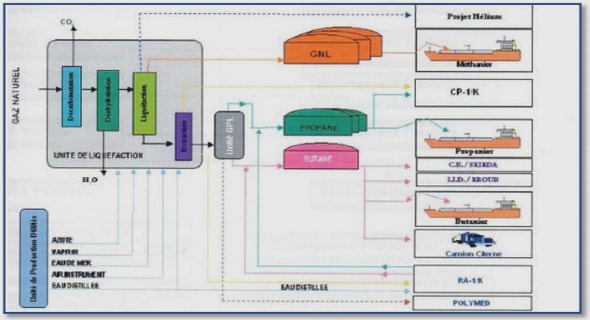
Get Complete Project Material File(s) Now! »
Boltzmann distribution density models
Besides auto-encoders, decoder networks and encoder-decoder networks (Section 2.2.2), another commonly used neural network for unsupervised feature learning is the restricted Boltzmann machine (RBM) [Smolensky, 1986]. An RBM is a variant of the Boltzmann machine [Hinton and Sejnowski, 1986]. These two probability density models fall into the family of recurrent neural networks with dynamics governed by Lyapunov (or energy) functions. Specifically, the probability density is given by the Boltzmann (or Gibbs) distribution.
Learning deep representations
A hierarchical architecture consists of multiple layers combined from series of basic operations. The architecture takes raw input data at the lowest level and processes them via a sequence of basic computational units until the data is transformed to a suitable representation in the higher layers to perform task, such as classification. Multiple layers of distributed coding allow the network to encode highly varying functions efficiently [Bengio, 2009]. An architecture with four or more representational layers is considered to be a deep architecture [Hinton et al., 2006; Bengio et al., 2006]. The learning of deep architectures has emerged, as an effective framework for modeling complex relationships among high-dimensional data and discovering higher-level abstractions. It learns a hierarchy of meaningful representations that carry some intrinsic value for classification tasks. As a result, deep learning methods have been suitably and successfully employed for a variety of problems, in domains like computer vision, audio processing and language understanding.
The current methods for learning deep architectures are a cumulation of much research over the years. Neural networks, popularized in the 1980s, revolutionized the notion of learning distributed representations from data. In particular, fully-connected multi-layered perceptrons, having been shown to be universal approximators, can represent any function with its parameters [Hornik, 1991]. However, researchers often have to deal with the problems of a huge number of parameters and the difficult non-convex optimization problem, which can become tedious and difficult to manage for deep networks [Bengio, 2009]. Recent algorithmic developments in unsupervised feature learning together with the ever increasing computational power of machines, enabled such deep networks to be trained.
This section discusses the main motivations and strategies for learning deep architectures and introduces three families of deep architectures and an adaption scheme to model image data using the convolution operator.
Motivations and strategies
A typical deep architecture takes raw input data at the lowest level and processes them via a sequence of basic computational modules, such as connectionist models (Section 2.2), until the data is transformed to a suitable representation in the higher layers.
Motivations. The main motivation for learning deep architectures is to discover abstraction from the lowest-level features to the highest-level concepts, either automatically or with as little human intervention as possible. The objective is to learn a hierarchy of representations, such that the representations at higher-levels are composed of lower-level ones. The deep hierarchical structure of the architecture is analogous to the multiple levels of abstraction that humans naturally describe the visual world [Bengio, 2009]. This multiple level structure also corresponds to the organization of neuronal encoding by the visual system in our brains [Karklin and Lewicki, 2008; Lee et al., 2008]. Besides these, the computational resources for training and inference should scale well with data cardinality and dimensionality, and the model should remain robust on noisy data.
From a representational point of view, a deep, yet compact, architecture is able to model complex functions more efficiently than a shallower architectures. Particularly, if a function is compactly represented by L layers, it may require an exponential number of units to represent the same function using only L − 1 layers [Bengio, 2009]. As a result, if an insufficiently deep architecture is used to model a complex function, the architecture might be very large to compensate for the loss in representational flexibility as compared to a deeper one. Just like their shallower cousins, deep networks have been shown to be universal function approximators [Sutskever and Hinton, 2008; Le Roux and Bengio, 2010].
Fully-connected deep architectures
There are three main families of deep architectures that originate from the various shallow unsupervised learning modules with fully-connected structure. They are namely: 1) deep belief networks [Hinton et al., 2006], 2) deep decoder-based networks [Ranzato et al., 2006] and 3) deep auto-encoder networks [Bengio et al., 2006]. The networks follow a similar general strategy of training by using greedy unsupervised learning followed by supervised fine-tuning. The main difference between the architectures is the choice of the basic building block. Deep learning is not restricted to connectionist models [Bengio, 2009; Deng and Yu, 2011].
Local connectivity and convolutional networks
In general, the fully-connected deep architectures presented above perform extremely well on modeling input data. However, due to the fully-connected structure between layers, it is difficult to scale up to handle high dimensional inputs, such as images. The images that these deep networks typically model only have a few hundred dimensions. For example, each image in the MNIST handwritten digit dataset [LeCun et al., 1998] is 28 × 28 pixels in size, resulting in a 784 dimensional input. An image with a size of 300 × 200 pixels, already has 60, 000 dimensions. Furthermore, modern digital camera sensors are capable of producing images with tens of millions of pixels. A dominant approach for modeling large images is through the use of local connectivity as inspired by the receptive field scheme proposed by Hubel andWiesel [1962]. The ideas were incorporated into an early hierarchical multilayer neural network known as the Neocognitron by Fukushima [1980]. The main concept is that parameters of the model are shared across various local patches of an image, resulting in invariance to spatial translation. In the 1980s and 1990s, LeCun et al. [1989, 1998] developed the convolutional neural network that can be trained using error backpropagation. It focused on tackling the vision problem through a fully-supervised multilayer network with convolution operators in each layer mapping their inputs to produce a new representation via a bank of filters. The model produced exceptional performances for vision problems, such as handwritten digit recognition [LeCun et al., 1989, 1998].
The convolutional operator naturally shares the parameters of the model by coding the image locally across various spatial locations in the image. This helps to scale the model for large images, while taking into account spatial correlations in the image. In addition, a sub-sampling operator is sometimes used to perform pooling in the filtered representation and reduces the spatially dimensionality of the representation. Figure 2.14 shows an example of such a convolutional network with convolution and sub-sampling performed successively. We shall see later that this approach of modeling images is not much different from other computer vision models (Section 2.4.1).
Table of contents :
Introduction
1.1 The image annotation problem
1.2 History, trends and opportunities
1.3 Contributions
1.4 Thesis outline
1.4.1 Recurring themes
1.4.2 Thesis roadmap
1.4.3 Chapter descriptions
Deep Learning and Visual Representations: An Overview
2.1 Introduction
2.2 Learning distributed representations
2.2.1 Feedforward neural networks
2.2.2 Auto-associative networks
2.2.3 Boltzmann distribution density models
2.3 Learning deep representations
2.3.1 Motivations and strategies
2.3.2 Fully-connected deep architectures
2.3.3 Local connectivity and convolutional networks
2.4 Modeling images using visual words
2.4.1 Pipeline of the bag-of-words model
2.4.2 Local feature extraction
2.4.3 Learning visual dictionaries for feature coding
2.4.4 Pooling
2.4.5 Maximum margin classification
2.5 Summary and discussion
Regularizing Latent Representations
3.1 Introduction
3.2 From neural coding to connectionist models
3.2.1 What is sparsity and selectivity?
3.2.2 Generic restricted Boltzmann machine regularization
3.2.3 Low average activation regularization
3.2.4 Sparsifying logistic
3.3 Representation regularization and regularizer design
3.3.1 Point- and instant-wise regularization
3.3.2 Generating jointly sparse and selective representations
3.3.3 Inducing topographic organization
3.4 Representation regularization experiments
3.4.1 Visualization: modeling natural image patches
3.4.2 Experiment: modeling handwritten digit images
3.4.3 Experiment: modeling color image patches
3.5 Potential extensions and applications
3.6 Summary and discussion
Deep Supervised Optimization
4.1 Introduction
4.2 Deep supervised fine-tuning: a quick recap
4.2.1 Deep error backpropagation
4.2.2 Up-down back-fitting algorithm
4.3 Top-down regularized deep belief network
4.3.1 Top-down regularization: the basic building block
4.3.2 Constructing a top-down regularized deep belief network
4.3.3 Three-phase deep learning strategy
4.4 Predictive and reconstructive encoder-decoders
4.4.1 Bottom-up and top-down loss functions
4.4.2 Globally optimized deep learning
4.5 Evaluation: Handwritten digit recognition
4.5.1 Results: top-down regularized deep belief network
4.5.2 Results: predictive and reconstructive encoder-decoders
4.5.3 Summary of results
4.6 Summary and discussion
Learning Hierarchical Visual Codes
5.1 Introduction
5.2 Single-layer feature coding
5.2.1 Unsupervised visual dictionary learning
5.2.2 Supervised fine-tuning of single-layer visual dictionaries
5.3 Hierarchical feature coding
5.3.1 Motivations of hierarchical feature coding
5.3.2 Stacking and spatially aggregating visual dictionaries
5.3.3 Top-down regularization of hierarchical visual dictionaries
5.3.4 Three-phase training of the bag-of-words model
5.4 Image classification experimental setups
5.4.1 Image classification datasets
5.4.2 Evaluation setup and metric
5.4.3 Experimental setup
5.5 Image classification evaluation and discussions
5.5.1 Evaluation: image classification results
5.5.2 Analysis: single-layer feature coding
5.5.3 Analysis: hierarchical feature coding
5.6 Summary and discussion
Discriminative Pooling
6.1 Introduction
6.2 Discriminative pooling optimization
6.2.1 Generalized pooling scheme
6.2.2 Parameterized pooling
6.2.3 Discriminative pooling optimization
6.2.4 Relationship between code selectivity and pooling
6.3 Discriminative pooling experiments
6.3.1 Evaluation: image classification
6.3.2 Analysis: how much to pool?
6.3.3 Analysis: where to pool from?
6.4 Potential methodological extensions
6.5 Summary and discussion
Conclusions
7.1 Learning deep visual representations: a synthesis of ideas
7.2 Future work
7.3 List of publications
Appendix
A Derivation of Gradients
A.1 Point- and instance-wise regularization
A.2 Squared loss penalty on activation averages
A.3 Cross-entropy penalty on decaying activation averages
A.4 Inverse temperature pooling parameters
A.5 Degeneracy pooling parameters
Bibliography