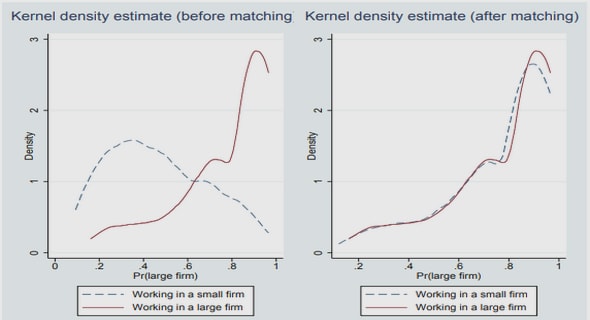
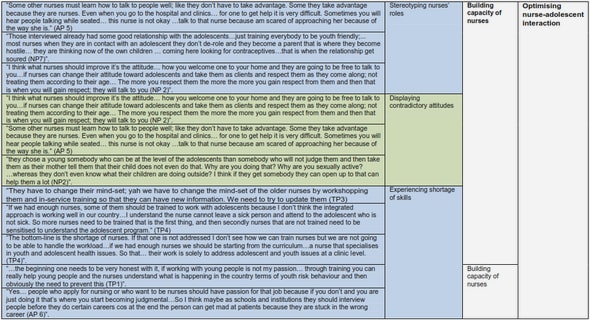
Get Complete Project Material File(s) Now! »
Key themes in the practice of differential privacy
Since its introduction in 2006, researchers have been stretching differential privacy in various ways to respond to the needs of different domains. While theoretical research into privacy has thrown up an avalanche of new definitions [16], privacy practitioners are left with many questions: which definition should I use for my dataset? How do these definitions compare? How do I interpret what privacy means? And – surprisingly, still – how do I choose epsilon?
Privacy breaches as inference attacks
The separation between the theory and practice of differential privacy is perhaps most notable in the way that experimental researchers investigate privacy breaches: they are usually described as inference attacks [17–21]. Inference attacks describe real adversarial threats to a system, pro-viding an operational scenario against which privacy mechanisms can be examined and (hope-fully) defend. For example, privacy researchers have found that the list of apps on a users smartphone can reveal sensitive attributes such as religion or relationship status [22] and can even be used to identify particular individuals [23]. The need for privacy-preserving techniques in these areas is precisely to protect against these sorts of inferences. Plausible deniability does not have this goal: inferences describe the potential for re-identification; plausible deniability simply ensures that there is no certainty of it. Differential privacy is careful not to guarantee protection against inference attacks – and indeed, is known to be susceptible to them [24] – despite this being a major concern for practitioners. Even if plausible deniability is the best we can hope for, reasoning about vulnerability to inferences is essential for communicating what privacy means and what sort of privacy is guaranteed for individuals whose data is entrusted to a curator. While there has been some work on incorporating inference attack models into the differential privacy guarantee9, the lack of significant research into the relationship between inferences and differential privacy means that there is still debate about what sort of protection differential privacy affords in practical adversarial scenarios [26].
How to choose epsilon
In the theoretical literature on differential privacy, the epsilon parameter in (1.1) is a privacy control; it describes both the “indistinguishability” level between secrets, and also the “privacy budget” available for subsequent data releases.10 However, in practical scenarios epsilon is usu-ally seen as a parameter for tweaking utility without associating any (specific) meaning to the resulting privacy guarantee [27]. Since epsilon is not meaningful to an end user, privacy prac-titioners can more easily brush aside concerns about its particular value. Indeed, Apple were lambasted for their cavalier use of differential privacy to provide some notional privacy to end users, without revealing that their chosen epsilon in fact provided next-to-no privacy.11 Even in situations for which differential privacy was explicitly designed, the question of how to choose epsilon? remains problematic [27–29]. Notably, this was an issue in the deployment of differ-ential privacy for the 2020 US Census; researchers remarked that the “literature of differential privacy is very sparse” regarding policies for choosing a value for epsilon [29]. In more complex domains, the relationship between epsilon and the privacy afforded is potentially very tenuous: in a text privacy scenario, how would the value of epsilon correspond to the privacy-protection afforded to the author of a document? And how does changing epsilon correspond to changes in the useful information released? A clearer understanding of the relationship between epsilon and the privacy-utility balance is necessary to ensure its proper use in differential privacy in new and complex domains.12
Managing the privacy-utility balance
Some of the early adopters of differential privacy were researchers in machine learning, hoping to ensure privacy-protection for individuals whose data was used to train machine learning models. One of the research questions which arose out of this context was where to add the noise?. Researchers found that they could squeeze more utility from a dataset by the judicious application of noise to different parts of the machine learning workflow [30, 31]. Despite these early insights, the methods for determining where to add noise in a workflow remain ad hoc and largely experimental.
In more complex domains, the question of how to add the noise? also becomes relevant. For example, in the text privacy domain, the addition of noise to words in a document might seem like a reasonable approach – but how should the noise be added to guarantee some privacy and utility? In geo-location privacy and standard differential privacy, there is a clear relation-ship between privacy and utility which determines the nature of the noise-adding mechanism that should be applied. Whereas in text privacy, the relationship between privacy and utility is unclear, which complicates the decision of how to add noise.
These questions underlie the need for a more principled approach to understanding the nature of the privacy-utility balance and how to compare systems wrt their privacy and utility properties.
Reasoning about utility
A related issue is the lack of tools for reasoning about the utility of a differentially private data release, thus requiring practitioners to resort to manipulating epsilon to an experimentally determined value. This sort of problem is not restricted to privacy practitioners working in new domains. In 2020, the US Census Bureau chose to apply differential privacy to their statistical data release mechanisms – precisely the domain for which differential privacy was designed.
Even in this scenario, the practitioners reported fundamental difficulties, particularly around the design of mechanisms for utility:
“Differential privacy lacks a well-developed theory for measuring the relative impact of added noise on the utility of different data products, tuning equity trade-offs, and presenting the impact of such decisions.” [29]
If in fact utility is the sole purpose of a data release, the absence of a sound methodology for reasoning about utility in differentially private data releases remains a critical weakness.13 And differential privacy’s claim of independence from the particulars of a dataset is a moot point if utility can only be evaluated through dataset-specific experimentation.
Goals of this thesis
The aforementioned concerns constitute foundational issues which act as obstacles to the more widespread practical application of differential privacy. This motivates a more general study of privacy and utility for new contexts, as well as a sound methodology for applying differential privacy in complex scenarios.
The goal of this thesis is to address these fundamental questions: How do I design mecha-nisms which provide some level of privacy and some level of accuracy for a domain in which the privacy or the utility requirements are not well understood? How do I decide how and where to add noise in order to achieve my privacy and utility goals? How do I interpret what privacy means in my domain? And how safe is my system against adversarial threats?
While the above concerns are not new – indeed many works in the literature have made contributions to our understanding of these areas – our goal is to approach this study under a unifying framework for reasoning about privacy and utility and to situate our work in the metric differential privacy context. In this way, we aim to equip privacy practitioners with the tools to reason about privacy and utility, and thereby to assist in the application of differential privacy to novel domains.
Contributions
In this thesis we examine some of the foundational questions around privacy and utility posed in the previous section with the overall goal of advancing the understanding and adoption of differential privacy in new domains. In particular, this work makes the following contributions:
We use the framework of Quantitative Information Flow (QIF) to examine questions around privacy and utility in metric differential privacy.
We explore the relationship between the epsilon parameter of metric differential privacy mechanisms and the safety of systems against adversarial threats. We show how the metric on the domain of inputs relates to how privacy is applied, which in turn affects the types of attacks that the system can defend against.
We model inference attacks against differential privacy and show that differential privacy’s protection against such attacks is dependent on the particulars of the dataset. We show that where the noise is added in a privacy workflow determines how the trade-off between privacy and utility can be managed, and what the setting of epsilon means in these scenarios.
We introduce a framework for reasoning about optimality based on a Bayesian model of util-ity. We show how the metric determines the classes of consumers for which optimal mecha-nisms exist. We use our model to re-evaluate impossibility results on optimality, discovering a new characterisation of optimal mechanisms and demonstrating that optimal mechanisms do exist contra existing results in the literature. Finally, we prove a new result on the universal optimality of the Laplace mechanism for continuous domains.
We present 3 new applications of metric differential privacy to problems of interest. We show why an understanding of the metrics involved is important for determining the type of privacy to apply. We also show how to reason about privacy and utility in each situation using the understandings developed in this thesis.
Synopsis
*This thesis is divided into 3 parts:
Part I: Foundations is intended as an introduction to the main technical material which forms the basis of the thesis.
– Chapter 2: Quantitative Information Flow introduces the QIF framework, which is an al-gebraic framework for modelling adversarial threats to secure systems by examining their in-formation flow properties. While its use in security has been well-established, the QIF model has not been extensively used in differential privacy.14 This chapter aims to provide a tutorial-style introduction to the basic QIF notation and results that are used extensively throughout the thesis. Of particular interest is the section on the geometry of hyper-distributions, which is a key motif used in this thesis, especially in the exploration of optimality in Chapter 6 and Chapter 7. This chapter is mainly based on material from the ‘QIF book’ by Alvim et al. [34].
Chapter 3: Metric Differential Privacy introduces the existing work on d-privacy, pioneered by Chatzikokolakis et al. [15] and on which this thesis builds. In this chapter we introduce the canonical example of geo-location privacy for which d-privacy is most well-known, the metric-based reasoning used for privacy and utility in the standard and local models of differential privacy, and some commonly used d-privacy mechanisms which will be encountered through-out. Our contribution in this chapter is to present the technical details in the language and notation of QIF.
Part II: Analysis contains the theoretical chapters representing the technical contributions of Aside from the works by Alvim et al. to establish strong leakage bounds using a channel model for differential privacy [32, 33].
Chapter 4: Comparing Privacy Mechanisms explores the privacy-based order induced by the epsilon parameter of differential privacy. We show that this order is strictly weaker than the secure-refinement order of QIF which models safety against adversarial threats. We introduce 2 new orders modelling threat scenarios: a max-case refinement order for reasoning about worst-case adversarial threats – in the spirit of differential privacy – and a metric-based order which quantifies over all metrics, allowing one to safely reason about differential privacy in certain contexts when substituting one mechanism for another. We show that both of these orders are strictly stronger than the epsilon-order, demonstrating that the epsilon parameter of differential privacy provides surprisingly weak guarantees of safety against a variety of at-tacks. Finally, we show how the privacy ordering wrt epsilon depends on the metric, and that comparing mechanisms wrt their safety against all adversarial threats is only safe, in general, within the same metric family of differential privacy mechanisms. (This chapter is based on the published papers “Comparing Systems: Max-case Refinement Orders and Application to Differ-ential Privacy” [35] and “Refinement Orders for Quantitative Information Flow and Differential Privacy” [36].)
Chapter 5: Inference Attacks examines the privacy-utility trade-off from the point of view of inference attacks. We use QIF to model inferences as the leakage of secrets via unexpected correlations, thereby providing a simple proof of the “no free lunch” theorem of Kifer et al. [37] which says that there are no mechanisms which are optimal for both privacy and utility. We provide an abstract model of noise-adding mechanisms based on where the noise is added – whether to the “secret” or to the “useful” parts of the data – and show that this determines what sort of control epsilon provides, either privacy control (in the former case) or accuracy control in the latter. We also show that the amount of privacy or utility that can be obtained by manipulating epsilon is determined by how this information is correlated in the particular dataset, and we demonstrate this in experiments on a medium-sized database. (This chapter is based on the published paper “On Privacy and Accuracy in Data Releases” [38].)
Chapter 6: Optimality I: Discrete Mechanisms introduces a framework for reasoning about optimal mechanisms for Bayesian consumers. Our work builds on the existing results of Ghosh et al. [39] for universal optimality of the Geometric mechanism; in this chapter we extend the study of optimality to metric domains and arbitrary classes of consumers using a novel ge-ometric perspective based on ‘hyper-distributions’. We formulate a new characterisation of optimality and use this to generalise and extend previous results in this area; importantly we discover new optimality results in the domain of “sum” queries, for which universal optimal-ity had previously been deemed impossible [40]. (This chapter is unpublished but is under preparation for submission.)
Chapter 7: Optimality II: Continuous Mechanisms uses the framework developed in Chapter 6 to prove a particular optimality result of interest: that the Laplace mechanism is uni-versally optimal for Bayesian consumers on a continuous domain in the same way that the Geometric mechanism is universally optimal in the discrete case. Our result is novel and is the first positive result on optimality for the Laplace mechanism, which has previously shown only to be non-optimal in various discrete settings. Our approach is made possible by the use of the algebraic framework of QIF, for which results on refinement naturally extend to the continuous domain, allowing the extension of our optimality results from Chapter 6 to the continuous setting. (This chapter is based on the paper “The Laplace Mechanism has optimal utility for differential privacy over continuous queries” [41].)
Part III: Applications presents new practical applications of metric differential privacy to prob-lems of interest.
Chapter 8: Statistical Utility for Local Differential Privacy shows how to apply metric-based reasoning to the problem of protecting the privacy of individuals while preserving some statis-tical utility, namely the ability to reconstruct the original (true) distribution of answers given a noisy distribution. We demonstrate experimentally, using geo-location points as a motivating example, that a mechanism designed for the Euclidean distance outperforms the (commonly deployed) mechanism for local differential privacy when the utility of the output is affected by the underlying ground distance between the estimated distribution and the true distribu-tion. (This chapter is based on the published paper “Utility-Preserving Privacy Mechanisms for Counting Queries” [42].)
Chapter 9: Text Document Privacy demonstrates an application of metric differential pri-vacy to a problem in text document privacy, namely hiding the writing style of an author. We demonstrate how to reason about privacy and utility in this space, interpreting what the privacy guarantee means for authors when differential privacy is applied to documents. We produce a novel d-privacy mechanism based on the Earth Mover’s distance and show, using ex-periments, that our mechanism provides reasonably good utility when outputting documents with the purpose of preserving their topicality. Our mechanism is the first of its kind in the domain of text document privacy, thus representing a genuinely novel application of differen-tial privacy. (This chapter is based on the published papers “Generalised Differential Privacy for Text Document Processing” [12] and “Processing Text for Privacy: An Information Flow Perspec-tive” [8].)
Chapter 10: Locality Sensitive Hashing with Differential Privacy explores a problem en-countered in recommender systems, namely how individuals can privately relinquish their purchase histories (or other sensitive item lists) to an untrusted data provider, who then re-quires some utility from the noisy release. We observe that a commonly used nearest neigh-bour search technique – Locality Sensitive Hashing – can be seen as a probabilistic mapping between metric spaces, and therefore permits metric-based reasoning about privacy and utility when used in conjunction with d-private mechanisms. We use this observation to construct an (approximate) d -private mechanism designed for the angular distance d which we show experimentally has reasonably good utility compared with its non-private counterpart. (This chapter is under submission and is available as the arXiv preprint “Locality Sensitive Hashing with Extended Differential Privacy” [43].)
Table of contents :
1 Overview
1.1 Background to differential privacy
1.1.1 Differential privacy and its applications
1.1.2 Metric differential privacy
1.2 Key themes in the practice of differential privacy
1.2.1 Privacy breaches as inference attacks
1.2.2 How to choose epsilon
1.2.3 Managing the privacy-utility balance
1.2.4 Reasoning about utility
1.3 Goals of this thesis
1.3.1 Contributions
1.3.2 Synopsis
1.3.3 Publications
I Foundations
2 Quantitative Information Flow
2.1 Modelling Systems as Channels
2.2 Modelling Adversaries
2.2.1 Vulnerability and Gain Functions
2.2.2 Posterior Vulnerability
2.2.3 Leakage
2.3 Comparing Channels: Refinement
2.4 Hyper-Distributions
2.4.1 The Geometry of Hyper-Distributions
2.4.2 Refinement of Hypers
2.5 Chapter Notes
3 Metric Differential Privacy
3.1 Definition and Properties
3.1.1 Technical Preliminaries
3.1.2 Definition of d-Privacy
3.1.3 Properties of Metric Differential Privacy
3.2 Geo-Indistinguishability – A Canonical Example
3.2.1 Utility Goals
3.3 Reasoning with Metrics
3.3.1 Oblivious Mechanisms
3.3.2 Local Differential Privacy
3.3.3 Reasoning about Privacy and Utility
3.4 Constructing d-Private Mechanisms
3.4.1 Other Metrics
3.5 Discussion and Concluding Remarks
3.6 Chapter Notes
II Analysis
4 Comparing Privacy Mechanisms
4.1 Motivating Examples
4.1.1 Technical Preliminaries
4.2 Average-Case Refinement
4.3 Max-Case Refinement
4.4 Privacy-Based Refinement
4.4.1 Comparing mechanisms by their “smallest « ” (for fixed d)
4.4.2 Privacy-based leakage and refinement orders
4.4.3 Application to oblivious mechanisms
4.4.4 Privacy as max-case capacity
4.4.5 Revisiting the Data Processing Inequality for d-Privacy
4.5 Verifying the Refinement Orders
4.5.1 Average-case refinement
4.5.2 Max-case refinement
4.5.3 Privacy-based refinement
4.6 Lattice properties
4.6.1 Average-case refinement
4.6.2 Max-case refinement
4.6.3 Privacy-based refinement
4.6.4 Constructing d-private mechanisms for any metric d
4.7 Comparing d-Privacy Mechanisms
4.7.1 Technical Preliminaries
4.7.2 Refinement order within families of mechanisms
4.7.3 Refinement order between families of mechanisms
4.7.4 Asymptotic behaviour
4.8 Conclusion
4.9 Chapter Notes
5 Inference Attacks
5.1 Motivation
5.2 Informal example: does it matter how to randomise?
5.3 Modelling Inferences
5.3.1 Quantitative Information Flow
5.3.2 Reasoning about Inferences
5.4 The Privacy-Utility Trade Off
5.5 Application to Differential Privacy
5.5.1 Utility-Focussed Privacy
5.5.2 Secrecy-Focussed Privacy
5.6 Experimental Results
5.7 Concluding Remarks
5.8 Chapter Notes
6 Optimality I: Discrete Mechanisms
6.1 Introduction
6.1.1 Motivation and Contribution
6.2 Modelling Utility
6.2.1 Universal optimality
6.2.2 The privacy context
6.2.3 Relationship to “counting” and “sum” queries
6.2.4 Our results on optimality
6.3 The Geometry of d-Privacy
6.3.1 The relationship between channels and hypers
6.3.2 The space of d-private hypers
6.3.3 Kernel and Vertex Mechanisms
6.4 Characterising Optimal Mechanisms
6.4.1 Existence of universally optimal mechanisms
6.4.2 Characterising universal L-optimality
6.5 Reasoning about Optimality
6.5.1 Loss Function Algebra
6.5.2 Classes of Loss Functions
6.5.3 Properties of Loss Function Classes
6.5.4 Identifying Optimal Mechanisms
6.6 Application to Oblivious Mechanisms
6.7 Optimality for d2-Private Mechanisms on f0: : :Ng
6.7.1 Kernel mechanisms
6.7.2 The geometric mechanism
6.7.3 Other optimal mechanisms
6.8 Optimality for dD-Private Mechanisms
6.8.1 Kernel mechanisms
6.8.2 The randomised response mechanism
6.8.3 Impossibility of universal optimality
6.8.4 Reframing the impossibility result for monotonic loss functions
6.9 Optimality for Other Metric Spaces
6.10 Conclusion
6.11 Chapter Notes
7 Optimality II: Continuous Mechanisms
7.1 Introduction
7.2 Preliminaries: loss functions; hypers; refinement
7.2.1 The relevance of hyper-distributions
7.2.2 Refinement of hypers and mechanisms
7.3 Discrete and continuous optimality
7.3.1 The optimality result for the geometric mechanism
7.3.2 The geometric mechanism is never « d-private on dense continuous inputs, eg. when d on X is Euclidean
7.3.3 Our result — continuous optimality
7.3.4 An outline of the proof
7.4 Measures on continuous X and Y
7.4.1 Measures via probability density functions
7.4.2 Continuous mechanisms over continuous priors
7.4.3 The truncated Laplace mechanism
7.5 Approximating Continuity for X
7.5.1 Connecting continuous and discrete
7.5.2 Approximations of continuous priors
7.5.3 N-step mechanisms and loss functions
7.5.4 Approximating continuous « d-private mechanisms
7.6 The Laplace and Geometric mechanisms
7.6.1 The stability of optimality for geometric mechanisms
7.6.2 Bounding the loss for continuous mechanisms
7.6.3 Refinement between N-Geometric and T;N-Laplace mechanisms
7.6.4 The Laplace approximates the Geometric
7.6.5 Approximating monotonic functions
7.7 Universal optimality for the Laplace Mechanism
7.8 Conclusion and Future Work
7.9 Chapter Notes
III Applications
8 Statistical Utility for Local Differential Privacy
8.1 Scenario: Estimating a Distribution
8.2 Comparing Mechanisms for Privacy
8.3 Comparing Mechanisms for Utility
8.3.1 Reconstructing the Original Distribution
8.3.2 Maximum Likelihood Estimation with IBU
8.3.3 Measuring Utility
8.4 Experimental Results
8.5 Conclusion
8.6 Chapter Notes
9 Text Document Privacy
9.1 Introduction
9.2 Documents, Topic Classification and Earth Moving
9.2.1 Word embeddings
9.3 Privacy, Utility and the Earth Mover’s Metric
9.3.1 Utility and Earth Moving
9.3.2 Implementing Earth Mover’s Privacy
9.3.3 Application to Text Documents
9.3.4 Properties of Earth Mover’s Privacy
9.4 Earth Mover’s Privacy for bags of vectors in Rn
9.4.1 Earth Mover’s Privacy in BRn
9.4.2 Utility Bounds
9.5 Text Document Privacy
9.5.1 Privacy as Indistinguishability
9.5.2 Privacy as Protection from Inferences
9.6 Experimental Results
9.7 Conclusions
9.8 Chapter Notes
10 Locality Sensitive Hashing with Differential Privacy
10.1 Introduction
10.1.1 Friend-Matching: Problem Setup
10.1.2 Our contributions
10.2 Locality Sensitive Hashing (LSH)
10.2.1 Random-Projection-Based Hashing
10.2.2 Privacy with LSH
10.2.3 Is LSH private?
10.3 LSH-based Privacy Mechanisms
10.3.1 Privacy Measures
10.3.2 Construction of LSHRR
10.3.3 Construction of LapLSH
10.4 Analyses of the Privacy Mechanisms
10.4.1 LSHRR: Privacy Guarantees for Hash Values
10.4.2 LSHRR: Privacy Guarantees for Inputs
10.4.3 LapLSH: Privacy Guarantees
10.5 Experimental Evaluation
10.5.1 Experimental Setup
10.5.2 Results
10.5.3 Discussion
10.6 Conclusion
10.7 Chapter Notes
11 Conclusions and Future Work
References
Appendices