Get Complete Project Material File(s) Now! »
Chapter 2 Related Work
In this section, we review the previous research work related to the information retrieval, social network, Online Knowledge Community, and the knowledge adoption model.
Search in Online Knowledge Communities and discussion forums
From the perspective of information retrieval, the difference between searching World Wide Web by Google and searching Online Knowledge Community is that user could ask his/her specific question directly to someone who already has relative experience or expertise. Hence, locating experts inside Online Knowledge Community is obviously helpful to improve the precision of the search engine when it searches Online Knowledge Communities. A lot of researchers have devoted their effort on developing an expert finder system, which can help others find appropriate expert to answer a question. The previous research works include “Answer Garden” by McDonald and Ackerman [7, 8]; “Contact Finder” by Krulwich B and Burkey C [9]; Krulwich described an approach to manage knowledge by focusing on self-organized activities of the organization’s members , which is called “expertise sharing” [10]; Kartz et al. explain the power of expertise locating for information retrieval by stating “Searching for a piece of information becoming a matter of searching social network for an expert on a topic with a chain of personal referrals from the searcher to the expert” [11].
Although above researchers did a good job on exploring the relationship of expertise of social network for the purpose of information retrieval. Either they only focus on finding experts or they didn’t combine finding experts with the searching knowledge in Online Knowledge Communities.
Xi et al. tried to use the Linear Regression and Support Vector Machines (SVM) to combine a few thread features and user information to create a ranking function for a newsgroup. However, this work only presents improvement in one of the IR performance measures over the baseline system. Plus, they didn’t exam their theory in the context of general OKC.
Online Knowledge Community Social etwork Analy sis
Community structure is important property of the social network. In the community structure, nodes are tightly joined together in knit groups (dense connections), between which only existing few nodes connected to the knit groups in a loose manner (sparser connections). Radicchi et al. give a general and quantitative definition of community network structure [12]. From the perspective of network topology, detecting the community network structure will help identify and further analyze the social network. Abramson, G. et al. analyzed a social network come up with plays of a video game [13]. It discovered the different topology between the social network and other networks, from regular lattices to random graphs. Also, this research work revealed the user behavior pattern is governed by the topology of the community. Girvan et al. propose a algorithm to detect the community structure [14]. They tested the network both in real world social network and simulated social network. The results shown that the algorithm could identify the community even the community structure is not well known. Guimera et al. studied a university’s email network evolution process [15]. The results suggested that self-organized social network, like email network could become into a state where the distribution of community sizes is self-similar. Newman et al. tried to come up with a quantitative algorithm to measure and detect the strength of community structure [16, 17]. In the first of their work, he designed an algorithm to divide the network into community structure by remove the edges, which is identified using one of a number of possible “betweenness” measures; in their second work, he expressed the social network measure “modularity” into modularity matrix (set of terms), which is used by his new designed algorithm. The results showed the benefit of the new algorithm which returns higher quality results.
Besides on mining the social network structure, researchers also used social network to examine Online Knowledge Community. Kou and Zhang [18] use social network structure to analyze the asking and replying network structure on a bulletin board system. Chiu et al. used social network as the major tool to analyze a professional virtual community [19]. It integrates the Social Cognitive Theory and the Social Capital Theory to investigate the possibility of members’ willingness to share knowledge with others. Y. Li et al. used social network as tool to analyze the community members’ knowledge sharing pattern [20].
It is an emerging study in the late 1990s to use statistics method to analyze the Online Knowledge Communities or online social network. The earliest attempt is on Usernet [21], which is a online newsgroup. Sack et al. focused mainly on visualization techniques to understand the social and semantic structure of Usernet [22]. Whittacker et al. [23] conducted an statistical data analysis on the Usernet newsgroups. Findings in their study include unequal levels of participation in newsgroups and cross-posting behaviors. Later on, Microsoft launched the Netscan website, which is a Usernet groups analysis/mining tool. The functions of Netscan include help users find their interested groups, identify the frequent posting authors, and track the growing of the threads. MA Smith et al. analyzed the tool and used it to mine the Usernet Groups in several dimensions [24-27]. Meanwhile, N. Matsumura et al. and Goh et al. studied others bulletin board systems by statistics method [28, 29]; Maloney-Krichmar used a two and half year statistics date of a online health support community to understand the community’s members dynamics interaction and the relationship between online participation and the individual’s off-line life [30]. Vicen et al. analyzed a technology news website Slashdot[31]. The Kolmogorov-Smirnov statistics tests were used. Important findings include degree distributions are better explained by log-normal instead of power-law distributions. By presenting the structure of discussion threads with radial tree, they also found that threads show strong heterogeneity and self-similarity.
Different from using statistics method to analyze social network, network centrality is commonly used as the indication of the importance of an individual in the network. In our study, we use the network centrality measures defined by Batagelj [1]. In our study, we use the common network centrality measures: Degree, Betweenness, Closeness and so on. We will explain the definition in the later section of the paper.
Generally speaking, in the context of Online Knowledge Community, members with high in-degree are the knowledge seekers, members with high out-degree are the knowledge contributors who actively response to others’ posts. A. Vilpponen et al. found that in electronic community network, higher in-degree centrality significantly reduces the adoption times [32]. Morrison et al. confirmed that higher out-degree centrality increases the decision time for knowledge adoption [33].
Different from Degree, definition of Betweenness is not so straightforward. Lots of research works are interested in finding the relationship between this centrality measure and information flow path way. Newman found that a social network, a node with high Betweenness will have significant influence over the spreading the information through the network. From another view of information flow, A. Mehra et al. resolved that a node with high Betweenness as one who is able to obtain information from most other members in the network [34]. Based on this, Newman concluded that Betweenness centrality measure can be an indicator of who the most influential people in a social network are [35].
Knowledge adoption model
The online forums always provide a score to represent the authority or trustfulness of the user. Normally, this score and user ID will be displayed together besides the user’s post. The purpose of displaying this score is giving reader a hit of how trustful the post content is coming from. However, we cannot rely on this score since it cannot reflect the user’s authority and trustfulness in a right way. Every forum uses their Ad-hoc way to calculate it. For example, in www.vbcity.com/forums/, the question post user can give score to the any of the reply, the corresponding reply user gain this score and use it to calculate his global user rating score.
Users of Online Knowledge Communities often come to seek knowledge that can be applied to their own applications. Therefore, we consider the search behavior in a knowledge-based 21
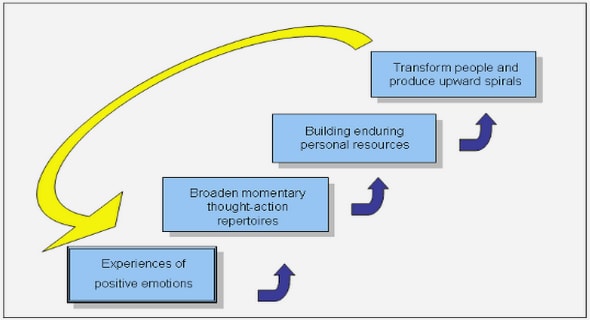
community as a knowledge adoption process. A knowledge seeker is interested in not only information relevant to his/her query, but information that he/she is able to comprehend and has confidence in the credibility and authority of the source. Based on the Elaboration Likelihood Model (ELM) [36], Sussman et al. proposed the Knowledge Adoption Model (KAM) [37] Figure 6. They found that a person’s intention to adopt knowledge was determined by two factors: the argument quality of the received message and the source credibility of the information source. According to the ELM, argument quality is the critical determinant of information influence when the message recipient is able to comprehend the message well. When the recipient is either unable or unwilling to process the message, indications of source credibility become a more critical role in the information influence process. However, the mechanisms underlying the interactions of the two factors in the information influence process appear to be complex [37].
Introduction to the Genetic Algorithm
Genetic Algorithm (GA) [38] is an evolution algorithm inspired by biology evolution process. It is one of the machine learning techniques.
GA is used in computing to approximate the global optimization solution. The basic element in GA is a population of abstract representations (called the chromosomes, the genotype, or the genome). Each individual of the population is a candidate solution. Similar to the biology evolution process, the population in the GA will evolve by producing the next generation. Normally, the first generation will be the randomly generated individuals. In each generation other than the first one, the fitness (quality) of every individual in the population is evaluated by a specific function (called fitness function). Then N best fit individuals will be directly selected into the next generation (called reproduction). Meanwhile, multiple individuals are stochastically selected from the current population, modified (called crossover) to form a new population, and varied (called mutation) from one to another. The new population is then used in the next iteration of the algorithm.
During the evolution, the global best fit individual (chromosome) or several best fit individuals are kept. The algorithm will be terminated when the global optimal solution meets the design value or when the number limitation of generation number is reached, or sometimes when the time limitation is met. To implement a GA, two key requirements are:
1. A fitness function, which is used to evaluate the fitness of the candidate solution. In the later section we will discuss that the fitness function is always problem defined. The design of a fitness function directly impacts its GA optimization performance.
2. An abstract representation model, also known as chromosome. The definition of the chromosome is also depends on the problem. Since each chromosome in the population is a candidate solution, the definition of chromosome should include all the elements that could be used to optimize the problem.
The process of GA can be presented in below pseudo-code:
Randomly generate (choose) the initial population
Evaluate the fitness of each individual in the initial population
Repeat until termination by the generation number limitation is reached, time limitation is reached or sufficient fitness is achieved.
Select global top fitness score individuals for reproduction (reproduction)
Create new generation through crossover and/or mutation (genetic operations)
Evaluate the fitness of each new individual
Replace the least fitness score individuals with new individuals
GA operators
Mutation
In GA, mutation is a genetic operator used to maintain genetic diversity from one generation of a population of chromosomes to the next. It is analogous to biological DNA mutation.
The purpose of mutation in GA is to avoid the algorithm getting trapped in a local optimal solution by preventing the population of chromosomes from becoming too similar to each other. This reasoning also explains the fact that most GA systems avoid only taking the fittest individual of the population in generating the next but rather a random selection with a weighting mechanism toward those that are fitter.
A common method of implementing the mutation operator involves generating a random variable for each bit in a sequence. This random variable tells whether or not a particular bit will be modified from its original state.
Crossover
Crossover is considered to be the Prime distinguished factor of GA from other optimization techniques. Crossover is a genetic operator that combines (mates) a pair of chromosomes (parents) to produce two offspring. It is analogous to the biological crossover.
The idea behind crossover is that the new chromosome may be better than both of the parents if it takes the best characteristics from each of the parents. Crossover occurs during evolution according to a user-definable crossover rate.
A common implementation of crossover operator involves choosing two individuals from the population, and breeding new offspring by combining portions of these individuals. Applying special selection pressure on the parent selection has been recognized as more effective than selecting parents randomly to improve the average problem solving quality of the population [39].
Prior Research of GA on Information Retrieval
GA has been used in information retrieval optimization since 1990s. Previous research works have applied GA into a wide range of Information Retrieval topics, for adaptation purpose.
Chen et al. applies the GAs in documents indexing [40].
Previous research works also apply the GA in query optimization field of information retrieval. Smith et al. use GA to create better Boolean query [41]. Yang et al. and Horng and Yel et al. introduce a novel approach to automatically retrieval keywords and adapt the keywords weight to improve the search precision [42, 43]. The experiment shown that using GA based approach to tune the retrieval keywords term weight is highly promising for application.
Fan et al. propose a Genetic Programming to tune the term weight strategies for ranking function [44]. In this work, relevance feedbacks were gathered together from user for a specific query to train the Genetic Programming system. Later on the same group further developed a Genetic Programming based optimization of context specific ranking function [45, 46]. The contribution of these research work demonstrate that machine learning tool like Genetic Programming and GA can help us train and discover a better ranking function by tuning the term weight. However, these work hadn’t exam the theory in the Online Knowledge Community data set.
Besides trying to optimize the ranking function in the web search design, Lopez-Pujalte et al. proved that retrieval order is a fundamental factor to be considered when design fitness function of the GA, which is used to optimize search by collecting user feedback [47]. Fan et al. exam the possibility to optimize the fitness function of the GA [48]. This work designed four new order-27 based fitness functions based on the web search utility theory. And compare these fitness functions with several existing order-based fitness functions on a large web corpus, part of which were shown as very effective.
Features Used in Online Knowledge Community Search
The chapter 1 has discussed the limitation of three ranking functions on the OKC documents. One of our research questions is “What are the additional criteria to rank documents inside the Online Knowledge Community?” We answer it here.
In this section, we propose two types of new criteria based on the Knowledge Adoption Model: Argument Quality and Source Credibility. The objective of these two types of new criteria is to help our new ranking function evaluate the helpfulness of the retrieved documents.
Argument Quality
The Argument Quality is our concept used to measure the thread content quality like how serious the user’s attitude is, the richness of the post text, how many users are contribute to the thread discussion, and how often users contribute to the thread discussion and so on. Based on our observation, we assume that more serious a user’s attitude is, or more words in the thread content, or more users contribute to the thread or more often users reply to the thread, more likely that the thread contains the solution to the problem. For the matter of this definition, I extracted below thread social interaction statistics as measures of the Argument Quality.
Table of Contents
Abstract
Acknowledgements
List of Tables
List of Figures
Introduction
1.1 An introduction to the Online Knowledge Community
1.2 An introduction to the social network:
1.3 The Social Network inside the Online Knowledge Community
1.4 The Limitation of Current Ranking Functions in Online Knowledge Community
1.5 Research Questions
Related Work
2.1 Search in Online Knowledge Communities and discussion forums
2.2 Online Knowledge Community Social Network Analysis
2.3 Knowledge adoption model
Chapter 3 New GA-based Ranking Optimization Algorithm for Online Knowledge Community Search
3.1 Introduction to the Genetic Algorithm
3.2 Prior Research of GA on Information Retrieval
3.3 Features Used in Online Knowledge Community Search
3.4 New Linear Ranking Strategy Discovered by GA
3.5 Design the Fitness Function
Experiments
4.1 Experiment Design
4.2 Data Collection
4.3 Building the Baseline
4.4 Query Selection
4.5 Label the Search Results
4.6 GA Experiment Procedure
4.7 Search Result Evaluation
Results and Conclusion
5.1 Training performance improvement
5.2 Training Set Improvement Statistics Table
5.3 Improvement by GA
5.4 Analysis and Discussion
5.6 Conclusion
Future work
References
GET THE COMPLETE PROJECT