Get Complete Project Material File(s) Now! »
Methodology
The following sections discuss the research methodology. It begins with research philosophy, research approach, research strategy and design, tools for data collection and data analysis. In the end, research ethic is also discussed.
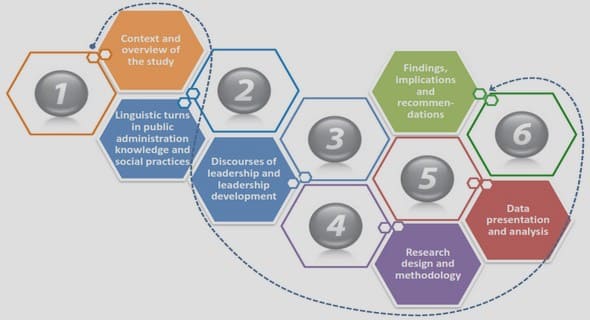
Figure 3.1 is displayed at the beginning of this chapter in order to help readers to make sense of our methodological approach. Furthermore, having a clear and concise visualization of the structure helped us when we conducted the research for this paper.
Research Philosophy
Saunders, Lewis and Thornhill (2009) refer to research philosophy as the development and nature of knowledge. An adopted philosophy will have far-reaching implications in terms of how to conduct the research itself. It will contain assumptions in regards to the research strategy and methods. This thesis adopts a positivistic research philosophy. In accordance to the research of Saunders et al. (2009), we will work with the observable social reality, gather data in form of a survey, analyze the data and derive generalizations out of it. The philosophy of positivism states, that facts are established by observing the reality. We used existing theory to develop our hypotheses as explained in the previous chapter. These hypotheses will be tested and thereby either confirmed or refuted. Easterby-Smith, Thorpe & Jackson, (2015) explain, that positivist observers must be independent from the researched variables in question and how human interests are neglectable as the world exists externally – thus the properties of said world can be measured rather than inferred through sensation or intuition.
Research Approach
A positivist research philosophy usually employs a deductive research approach and further down the line a collection of quantitative data. Saunders et al. (2009) explain five sequential stages that a deductive research will progress through:
deduction of a hypothesis from the theory
propose correlations between two specific concepts or variables
hypothesis testing
examination of the specific outcome of the inquiry
if necessary, modification of the theory in the light of the findings
A deductive research tends to have specific characteristics. These attributes involve the quantification of concepts and an indication of how variables are to be measured. Adding to this, control variables and a highly structured and rigid methodology are important, as this allows for a reliable replication of the thesis. Moreover, a fixed and predetermined structure will ensure accuracy in measurement. Finally, in order to generalize the findings a sufficient amount of observations, in terms of numerical size, is needed (Kumar, 2005; Saunders et al., 2009).
Our data collection will occur via a survey. However, we do not believe that we can fully answer our proposed hypotheses with this information alone. As such, we will conduct focus groups in order to gain complementary material. While uncommon, a positivist philosophy can be used for interviews and the likes thereof. Therefore, the main part of this thesis will be quantitative whereas additional data will be gathered in a qualitative manner. Our research is thus a mixed approach design.
Research Strategy
Our research strategy consists of two parts – those being a quantitative and a qualitative analysis. Each part requires a shift in mindset and different approaches in the collection of data. While the methodological approach of this thesis is considered as a mixed methods research approach – that being the synthesis of the aforementioned strategies – we want to emphasize that the quantitative data collection and analysis are the main focus.
Quantitative Part
Quantitative researches are often used as synonyms for data collection techniques or analysis methods that generates or uses numerical data (Saunders et al., 2009). Creswell (2013) explains that this type of research is used for testing theories by investigating the relationship between variables. The variables can be measured and analyzed by using statistical procedures. As mentioned in 3.2, deduction and generalization are characteristics of this type of research. In order to get to this point, however, one must control alternative explanations and find a way to address bias. This paper sees a collection of quantitative data in form of a survey which will be further explained in 3.4.2. Saunders et al. (2009) describes that surveys are a popular form of business and management research, as it helps to answer the “who, what, where, how much and how many” (p. 144) questions. Surveys allow gathering a large amount of data from a significant part of the population in an economical way. The survey strategy we employ will take form of a questionnaire. Our questionnaire consists of 16 questions and can be viewed in the appendix. Three of these will be aimed at the person him-or herself. We ask for age, gender and approximate budget for their impulse buying. The remaining 13 questions are aimed to shed light on our hypotheses. In order to find supporting or disproving data. We employ a Likert scale in order to find the significance of various influences on our factor post purchase regret. With said Likert scale we can measure the agreement or disagreement of our participants.
Qualitative Part
Qualitative researches, on the other hand, are often synonymous to data collection techniques or analysis methods that generates or uses non-numerical data (Saunders et al., 2009). Creswell (2013) further describes that this approach is used for exploring and understanding issues in depth. This thesis will employ a qualitative gathering of data in form of focus groups, which will be explained further in detail in 3.4.2. Our topic of impulsive purchasing is deeply connected to the area of human psychology. Quantifying human behavior is a daunting task. Interrelating relationships and blurry lines between causalities deems quantitative approaches in social science as difficult to go about. Thus, in order to be able to fully understand the ramifications of our study we will employ a qualitative data analysis in conjunction to our quantitative one. By doing so, we hope to be able to avoid misinterpretation and find discrepancies or supporting data.
Data Collection
According to Hox & Boeije (2005) two types of data can be involved in data collection of academic research: primary data and secondary data. Primary data is about collecting first-hand data for reaching a specific research purpose, which can be gathered through interviews, observations, experiments and questionnaires (Hox & Boeije, 2005). In contrast, secondary data refers to the data that was collected first-hand by other persons.
Sampling technique
According to Saunders et al. (2009) it is impossible or impracticable to survey or analyze an entire population due to the restriction of time, money as well as access, which means sampling has become a necessity and not an option. Within this study, we have decided that our selected sample are students at the Jönköping University. We applied the non-probability sampling technique, which is defined as “the probability of each case being selected from the total population is not known and it is impossible to answer research questions or to address objectives that require you to make statistical inferences about the characteristics of the population” (Saunders et al., 2009, p213). Convenience sampling is also one of the methods that will be mainly used. The convenience sampling method refers to data, which is collected randomly in the most effective way, taking different factors into consideration such as access, time and cost. To be specific, we will use tablets borrowed from the Jönköping University Library to ask students that had impulse purchasing experience to answer our questionnaire. By doing so, we can collect sufficient reliable data in a short period of time without the risk of having an unanswered online survey. The following Figure 3.2 illustrates an overall view of sampling techniques for this study.
We used convenience sampling for the two conducted focus groups. All the participants are students that gave us their consent to use their experiences and opinions for this thesis. We will use the gathered data as supplement and complement for our collected data from the questionnaire as mentioned in 3.3.2. We will draw out differences, discrepancies or supporting evidence.
Primary Data
Within this research, our primary data will be mainly collected through a questionnaire, since the best use of a questionnaire is when the business and management research strategy is designed as a survey (Saunders et al., 2009). According to Ghauri and Grønhaug (2005) the general application of a questionnaire is to test a theory by collecting data and researchers need to define a theory from previous literatures in order to test the relationship between variables. Therefore we believe that a questionnaire is the most appropriate method for our primary data collection. Saunders et al. (2009) pointed out that the questions must be designed precisely before collecting data in order to answer the research question as well as to meet the research purpose. The questionnaire is unlike an interview (such as in-depth or semi-structured) that enables a researcher to explore issues further during the conversation. It only provides one chance for the researcher to collect data, as respondents will not re-answer your questionnaire. This means that if the questions are not well designed, the issue of validity and reliability of data will occur (see further discussion in 3.6).
The design of questionnaire can be generally categorized into two types (see Figure 3.3) according to the difference of if a questionnaire is self-administered or interviewer administered. In this study, we have chosen the latter, a self-administered design of a questionnaire, as we need our planned questions to be completely answered by respondents
Within this research, we use the a seven-point Likert-style rating scale to design the questions in the questionnaire (see Appendix 8.2), which asks about the opinion of respondents that in which level they agree or disagree with statements posted in the questionnaire, ranging from strongly disagree (1) to strongly agree (7). These questions are designed correspondingly with the proposed hypotheses in order to collect empirical data. The questionnaire uses two types of questions and has an overall of 16 questions. Three of those ask about the background information of a student including age, gender, and their usual spending range of impulse purchase. The remaining 13 are questions scaled on a Likert scale. They are are meaningfully designed to answer the research purpose on what the triggers of buyer regret from impulse purchase are. One should be careful when formulating hypotheses as well as measurements or questions for it, since it has significant effect on the internal validity (Cooper & Schindler, 2008). In order to ensure the internal validity of our research, we used a study from Lee and Cotte (2009) on post purchase consumer regret as our guidance to the formulation of measurements and questions. The following table 3.1 will indicate the support references for hypothesis making and measurements/questions formulation.
Saunders et al. (2009) draw out the general differences between quantitative and qualitative data as follows: the former derives its meaning from numbers, its collection results is usually in numerical or standardized data and the analysis will be carried out through diagrams and statistical means. In contrast, qualitative data derives its meaning through words, the collection results are in non-standardized means and require categorization and the analysis is conducted through the use of conceptualization. Because of this and in order to gain a comprehensive understanding on this study, we have also chosen the focus group as complement method for primary data collection, as discussed above in section 3.3. The focus group is sometimes called “focus group interview” – it aims to get an in-depth understanding on a particular issue by an interactive discussion amongst participants (Carson, Gilmore, Perry & Gronhaug, 2001). Saunders et al. (2009) suggest that a focus group interview is generally used to understand the reasons behind the decisions made by participants, or to explore a deeper understanding of their attitudes towards the research purpose. In addition, it can encourage the interaction amongst participants and get more control on the focus.
Krug and Casey (2000) also described the main feature of focus groups being the aforementioned interactions among participants as “information rich”.
Within this study, the design of focus group interview is semi-structured because:
It could lead the discussion into some significant areas that helps in addressing our research question and purpose that we had not taken into consideration previously;
It could motivate and encourage each participant to think aloud about things that they may have never thought about. Thus, as a result we might be able to collect rich primary data (Saunders et al., 2009).
However, one should note that when conducting a semi-structured interview: The researchers should have a clear theme and guiding questions(s) prepared to prevent a slip into out-of-the-topic fields.
Secondary Data
The secondary data that we have collected are from previous studies, mainly peer reviewed papers, including journals, articles, reports as well as books. The search engines we used are: Scopus, Web of Science, Primo from Jönköping University Library and Google Scholar. There are two uses of secondary data collection that we employed: first, through a literature review we found our research gap, which is stated in the problem discussion section of this thesis. Second, it provides a solid theoretical background for the formulation of the hypotheses, analysis and discussion for empirical findings.
Approach to Data Analysis
In this section, we describe how the collected data is quantified and made sense of. As we employed both, a survey and two focus groups, we have various methods and approaches we can use. We will go in depth into these starting with the analysis of the quantitative data, which was the result of the used questionnaire. Afterwards, a description of the categorization scheme will be provided from our qualitative data – being the result of the focus groups.
Analyzing Quantitative Data
The method we have chosen to analyze the quantitative data collected through the questionnaire is structural equation modeling (SEM) with AMOS. AMOS is an extension of the statistics software SPSS – it is a tool to analyze our quantitative data. According to Byrne (2009) structural equation modeling is a “statistical methodology that takes a confirmatory (i.e. hypothesis-testing) approach to the analysis of a structural theory bearing on some phenomenon” (Byrne, 2009, p3). Bentler (1988) describes this model as a causal process between different variables. This means that SEM is a general statistical modeling technique used to establish relationship among variables. Moreover, SEM has significant advantage to analyze or study latent variables, so called factors.
Generally speaking, SEM calculates all variables at the same time in a given model rather than each coefficient separately. In other words all relationships between the variables are evaluated simultaneously (Alavifar & Karimimalayer, 2012). A benefit of this approach is therefore that the measurement error is not aggregated in a residual error term (StatisticsSolutions, 2017). Next, the output of AMOS provides extensive goodness of fit statistics, which in turn heightens the reliability and validity of our model (Alavifar & Karimimalayer, 2012). To contrast, regression modelling analyzes the most commonly used index for reliability, being the R-squared factor. Additional indices, such as lack-of-fit sum of squares or reduced chi-squared require additional effort. The type of factor analysis that is applicable to our study is a so-called path analysis; which can be seen as an extension of the multiple regression model. Garson (2008) explains that path analysis is used to test estimates of magnitude, significance and causal correlations between variables. The path diagram itself is usually visualized in a circle and arrow figure, with single headed arrows indicating causation. Garson (2008) further explains that the regression weights for the variables and a goodness of fit statistic is calculated.
According to Saunders et al. (2009) when testing a proposed model, the model assessment procedure should be kept in the mind in order to ensure the credibility of research. Once the model is established, the researchers “should test its plausibility based on sample data that comprise all observed variables in the model” (Byrne, 2009, p7). The model assessment procedure can be explained as the level of goodness of fit between the proposed the model and sample data (Byrne, 2009; Hooper, Coughlan & Mullen, 2008). Within AMOS, there are important parameter values yield to estimate the goodness of model fit, such as Goodness of Fit Index (GFI), Chi-Square (X²), Root Mean Square Error of Approximation (RMSEA) and the likes thereof, which guarantee the reliability and validity of the proposed model. By taking the discussion above into consideration, we believe that SEM with AMOS is the most appropriate method to analyze the quantitative data because of its strength of prediction in models in which consists of latent variables.
Table of Contents
1. Introduction
1.1 Background
1.2 Problem Discussion
1.3 Purpose
1.4 Research Question
1.5 Perspective
1.6 Delimitation
2. Frame of References
2.1 Terminology
2.2 Theoretical Background of Hypothesis
2.3 Proposed conceptual model
3. Methodology
3.1 Research Philosophy
3.2 Research Approach
3.3 Research Strategy
3.4 Data Collection
3.5 Approach to Data Analysis
3.6 Validity and Reliability
3.7 Research Ethics
4. Empirical Findings and Analysis
4.1 Descriptive Analysis
4.2 Model fit test within AMOS
4.3 Reliability test of Cronbach’s Alpha
4.4 Hypotheses analysis
4.5 Complementary result
4.6 Analysis of the Focus Groups
5. Conclusion
6. Discussion
6.1 Discussion on Findings
6.2 Discussion on Methodology
6.3 Discussion on Practical Implication
6.4 Discussion on Limitation
6.5 Future Research Suggestion
7. Reference list
GET THE COMPLETE PROJECT
The Triggers of Buyers Regret of Impulsive Purchases