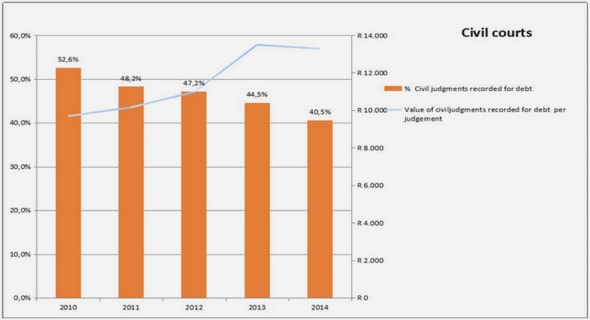
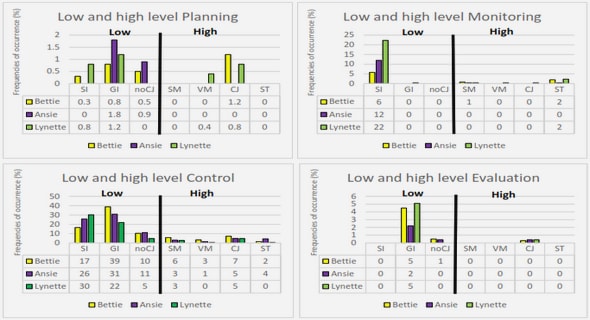
Get Complete Project Material File(s) Now! »
Estimation of road distress indicators/statistics
The main rationale behind the development of these methods is either to automate the distress identification procedure which is highly manual and subjective due to its over-reliance on expert knowledge and interpretation, or to find alternatives for more computationally demanding identification schemes. Investigation of neural networks as replacements for subjective expert ratings constitutes most of the earliest studies. For example, Eldin and Senouci (1995) use a feed-forward neural network as a substitute and possible replacement for a more rigorous mathematical model developed by the Oregon State Department of Transportation (OSDOT). The OSDOT model consists of a long, stepwise calculating algorithm based on cracking, and rutting indices on alligator, transverse cracks, block cracks, patching, bleeding, and rutting distresses. Their results indicate that the ANN outperforms the OSDOT model in estimating subjective condition ratings performed by the maintenance personnel for similar portions of two interstate highways. Banan and Hjelmsted (1996) show that a Monte-Carlo Hierarchical Adaptive Random Partitioning (MC-HARP) algorithm (a type of neural network) outperforms the well-established formula developed by the American Association of State Highway Officials (AASHO) in estimating road durability of road Sections. This is later confirmed by Terzi (2007) who achieve similar results in modeling the Road Serviceability Index (PSI) of flexible roads. He alleges that the proposed approach can be easily and realistically used to replace more complicated models for solving complex problems. Heiler and McNeil (1997) propose the ANN as a replacement for the onerous manual segmented procedure for road condition assessment using GPR data. Van der Gryp, Bredenhann, Henderson and Rohde (1998) use a one-hidden-layer feed-forward neural network to estimate the Visual Condition Index (VCI) which is normally calculated from visual road condition data and requires the selection of a weighting factor for each type of distress.
Attoh-Okine (2001) demonstrates the use of ANN self-organizing maps for the grouping of road condition variables in developing road performance models to evaluate road conditions on the basis of road distresses. Xiong (2001) uses analysis of sort functions of ANN and the diagnostic technique of road surface distress, to perform diagnostic function on roads. A most recent study is reported by Zakeri, Nejad, Fahimifar, Torshizi and Zarandi (2013) who replace expert rating with a system based on wavelet modulus and 3D Radon Transform (3DRT) for road distress detection and classification. The features and parameters of the peaks are finally used for training and testing the ANN classifier. The proposed approach yields very good performance and the researchers conclude that this high performance demonstrates the advantages of this method in correct classification of road cracking. Though visual inspection is still a popular method of acquiring road surface condition data, it is highly unreliable due to its proneness for inconsistency from one data collector to another. Thus, as part of the initiative for automation of road damage identification procedure, road images have been collected and applied to ANN models. Kaseko et al. (1991-1994) use MLP neural networks to identify transverse, longitudinal, alligator, and block cracks through image processing on road images for the U.S. Strategic Highway Research Program. Later, Nallamothu and Wang (1996) use the radial basis neural network on the same images to identify similar cracks and they find that 85 % of the patterns are identified correctly. Garrick, Kalikiri and Achenie (1994) develop an automated system using the pattern recognition capabilities of ANNs to characterize common road distress features like cracks, patches and potholes.
Tillotson, Snaith and Huang (1998) also apply a massively-parallel computer system called a Distributed Array of Processors (DAP) in which 1024 processors work simultaneously on a digitized road image to determine whether or not there are cracks in an image in real-time. They show that they are able to achieve about 80% success. Recently, Mokhtarzade and Zoej (2007) apply the approach to high-resolution satellite images. Xu, Ma, Liu and Niu (2008) exploit the self-studying feature of ANNs to identify surface cracks from real road images. By converting cracking recognition to the cracking probability judgment for every sub-block image, cracking trend is calculated, and a method for revising the neural network output is shown to increase accuracy of identification. Yu and Salari (2011) use ANNs to develop an efficient and more economical approach for road distress inspection from laser image data. García-Balboa, Reinoso-Gordo, and Ariza-López (2012) use ANN to develop a method and tool for automatically evaluating road quality. It is found that the ANN achieves over 70% correlation with expert scores for all the test cases.
A number of recent studies have also compared performances between one type of neural network and another or neural network models and regression models. For example, Fajardo (2011) compares the performance of Support Vector Machines (SVM) and ANN as tools for determining the visual condition of roads on traffic data. The results show that, with data of similar dimensions to the one used in creating it, the ANN performs better classification than SVM. Shahnazari, Tutunchian, Mashayekhi and Amini (2012) show that an ANN-based model is more precise than a GP-based model in estimating PCI. Chandra, Sekhar, Bharti and Kangadurai (2013) compare the performances of an artificial neural network with linear and nonlinear regression models by investigating the relationships between road roughness and distress parameters such as potholes, raveling, rut depth, cracked areas, and patch work. The road distress data collected on four national highways in India using a network survey vehicle (NSV) are used to develop linear and nonlinear regression models between roughness and distress parameters. Analysis of variance of these models indicates that the nonlinear model is a better estimator than the linear model. R2 value, root mean square error (RMSE), and mean absolute relative error (MARE) also yield similar results. Then an artificial neural network with five input nodes, 15 hidden nodes, and one output node is developed and trained with 90% of the data and tested with remaining 10% data. When the performance of the ANN model is compared with that of linear and nonlinear regression models, it is found that its mean absolute error (MAE) is around 18% less than that for the linear model and 11% less than that for the nonlinear model, and its MARE values are 12.5% lower than both linear and nonlinear regression models which implies that the ANN model performs much better in estimating the road roughness from the given set of distress parameters.
Definition and architecture
Haykin (2009) defines an artificial network as a massively parallel distributed processor made up of simple processing units that has a natural propensity for storing experiential knowledge and making it available for use. It resembles the human brain in that it acquires ‘knowledge’ through a learning process and that ‘knowledge’ is stored in interconnection weights just like the brain’s synaptic weights. The learning process involves adjusting the interconnection weights until they meet a certain goal. Figure 4.1 shows a clearly labelled diagram of a typical artificial neural network model. In Figure 4.1, the weights are used for ‘weighting’ the inputs and may lie in the range that includes negative as well as positive values. An activation function moderates the amplitude of the output. There are three main types of these functions namely, the threshold function, the linear function and the sigmoid function. The threshold function produces outputs that are either 1 or zero depending on the range of the weighted input values. It is largely used in pattern classification problems. The sigmoid function is by far the most common activation function and gets its name from its s-shape that is perfectly blended between two t-ordinates. It has two main variations: logistic sigmoid function which characterised by s-shaped fit between zero and +1, and the tangent sigmoid (hyperbolic) function which assumes values between ±1.0. Though by design, the range is actually ±1.7159 to allow for the squashing effect of the sigmoid function. The linear function reproduces the inputs with or without a scale. When it reproduces the inputs without scaling them, it is termed pure-linear function. This is the most common form of the linear functions.
ANN generalisation
Generalisation is when a neural network is able to produce a correct input-output mapping even when the input was not the one used during its training process (Haykin, 2009). The goal of neural network training is not to learn the training data exactly and fail to generalise its response over fresh data extracted from similar set. Any properly designed ANN model should be able to replicate its performance, with comparable accuracy, over data that has not been seen before. Generalisation is influenced by three factors: the size and representativeness of the training sample to the operating environment; the architecture of the neural network; and the physical complexity of the problem (Haykin, 2009). The training sample should be as representative as possible to the prevailing operating conditions. The data should cover as much as possible of the space of the data being generated by the process under investigation. In other words, it is necessary to ensure that the training data contain all of the important spectral properties typical of data generated by the system under all key operating conditions. This obviously requires a proper prescription of the operating conditions with respect to function approximation problems since they are often too dependent on these conditions.
In polynomial curve fitting, it is observed that when the polynomial coefficients are too few, the polynomial is too inflexible so that it fails to give good approximations over new data, on the other hand, when the coefficients are too many, the polynomial fits too much of the noise on the data that was used to build the polynomial. This is also experienced in designing of neural network models. Therefore, in order to achieve good network generalisation, there is need to find a way of controlling the complexity of the network architecture. In the case of artificial neural networks this is achieved by changing the number of adaptive parameters in the network (Bishop, 1995). One way to address this problem is to compare a range of models with different complexities and then select the one that seems to yield optimal performance. The other more automatic way is through cross-validation. The training set is partitioned into three data sets: estimation set, validation set and test set. The main rationale is to validate the model on a different data set from the one that is used in training it and then, in order to avoid over-fitting the validation data set, the network is further tested on another data set. This is a more practical approach and it is the one which has been employed in this study. Haykin (2009) recommends this approach for designing large networks with good generalisation.
Problem complexity results in loss of quality in the network generalisation with similar training data and network architecture. Besides, there is no guarantee that any two similar physical problems at different levels of complexities though being modelled by similar neural networks will experience similar quality in network generalisation. This is where ANN design has sometimes been argued to be a combination of science and art.
Chapter 1
1.1 Introduction
1.2 Study objectives
1.3 Road deterioration and need for maintenance
1.4 Current road management and maintenance systems
1.5 The developed methodology
1.6 Scope of work
1.7 Thesis layout
Chapter 2 Literature review
2.1 Introduction
2.2 Real-time road management systems (RTRMS)
2.3 ANN-based systems
2.4 Concluding remarks on ANN-based methodologies
Chapter 3 Road-vehicle interaction
3.1 Vehicle ride dynamics
3.2 Transmissibility
3.3 Determination of road profiles and dynamic tyre forces
3.4 Road surface topography
3.5 Conclusions
Chapter 4 Theory of ANN modelling for road-vehicle interaction
4.1 Introduction to inverse problem solution
4.2 Artificial neural networks (ANN)
4.3 ANN architectures and formulations
4.4 Comparison of network performances
4.5 Model validation
4.6 Conclusions
Chapter 5 Development of a generic methodology
5.1 Data acquisition
5.2 Data preparation
5.3 ANN identification
5.4 ANN simulation
5.5 Road condition identification
5.6 Methodology verification via case studies
5.7 Conclusions
Chapter 6 Numerical case study
6.1 Introduction
6.2 Customisation of the proposed methodology to this case study
6.3 Theory
6.4 Description of the vehicle dynamics
6.5 Numerical studies
6.6 Conclusions
Chapter 7 Experimental case study
7.1 Introduction
7.2 Land Rover properties, suspension and numerical model
7.3 Nominal road profiles
7.4 Generating the training data
7.5 ANN architecture and training
7.6 Response measurements
7.7 Simulations, results and discussions
7.8 Conclusions
Chapter 8 Field tests on mine vehicles
8.1 Introduction
8.2 Materials and methods
8.3 Measured data and selection of training data
8.4 Results and discussions
8.5 Conclusions
Chapter 9 Conclusions
9.1 Introduction
9.2 Detection, quantification and location of road damage as it occurs in real time
9.3 Better understanding on the application of ANN to function approximation problems
9.4 Influence of road and vehicle operating factors affect the identification process
9.5 Influence of vehicle suspension characteristics affect the identification process
9.6 Summary of key findings from the case studies
Chapter 10 Recommendations for further study